Simon Malan, Benjamin van Niekerk, Herman Kamper
Published at ICASSP 2025:
10.1109/ICASSP49660.2025.10890719
Code:
PromSegClus,
ES-KMeans+
Abstract: We look at the long-standing problem of segmenting unlabeled speech into word-like segments and clustering these into a lexicon. Several previous methods use a scoring model coupled with dynamic programming to find an optimal segmentation. Here we propose a much simpler strategy: we predict word boundaries using the dissimilarity between adjacent self-supervised features, then we cluster the predicted segments to construct a lexicon. For a fair comparison, we update the older ES-KMeans dynamic programming method with better features and boundary constraints. On the five-language ZeroSpeech benchmarks, our simple approach gives similar state-of-the-art results compared to the new ES-KMeans+ method, while being almost five times faster. Project webpage: https://s-malan.github.io/prom-seg-clus.
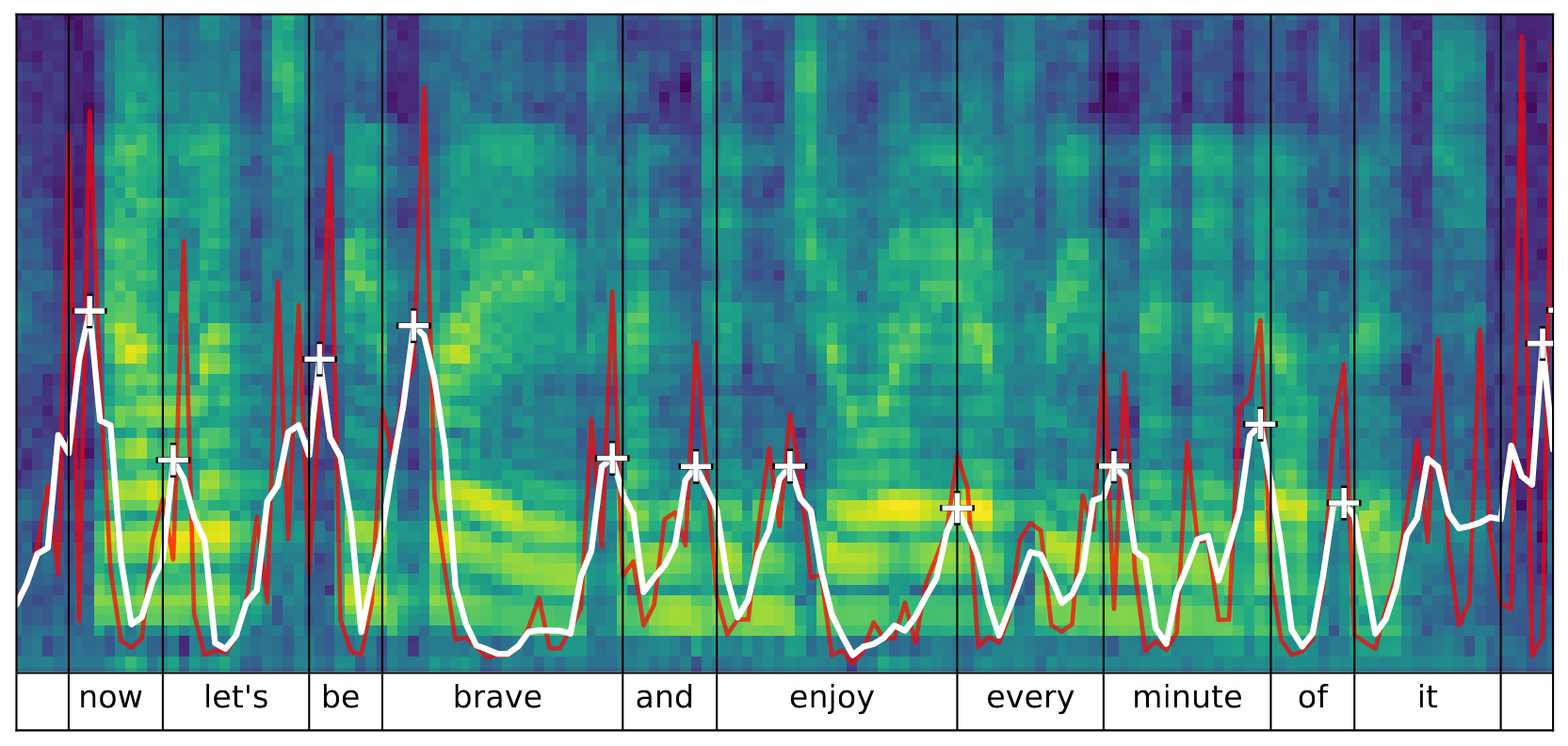
First we look at the word segmentation step used in both Prom. Seg. Clus. and ES-KMeans+. The method is first introduced by Pasad et al. in the paper at https://arxiv.org/abs/2307.00162 titled: What do self-supervised speech models know about words?
Figure 1 shows an example of the prominence based approach. The code for this step can be found in our GitHub repository: https://github.com/s-malan/prom-wordseg. The boundaries can be tuned using the parameters (distance, window_size, prominence) described in the README. These boundaries serve as input to the lexicon building step described next.
Using the prominence-based word boundaries, we can build a lexicon by simply clustering these boundaries (like in Prom. Seg. Clus.) or we can use dynamic programming to sub-select boundaries which are then used to build the lexicon (like in ES-KMeans+).
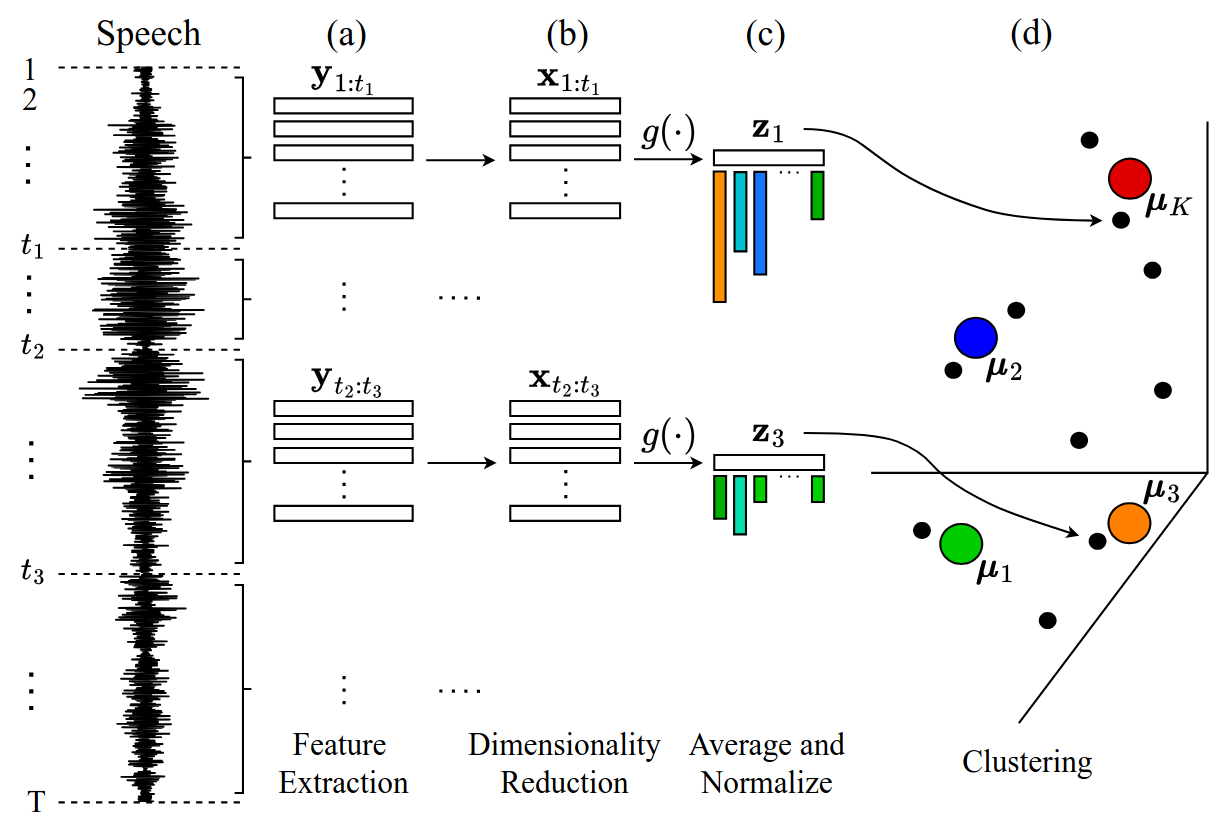
Figure 2 shows the lexicon building step. Both Prom. Seg. Clus. and ES-KMeans+ use this step. Prom. Seg. Clus. directly builds a lexicon like in Figure 2 using the prominence-based boundaries of Figure 1, the full codebase can be found in our GitHub repository: https://github.com/s-malan/prom-seg-clus. ES-KMeans+ also builds a lexicon like in Figure 2 but, after extracting prominence-based word boundaries like in Figure 1, it iteratively clusters and re-segments the utterance to select a near-optimal subset of word-like boundaries with its corresponding lexicon. The full codebase for ES-KMeans+ can be found in our GitHub repository: https://github.com/s-malan/es-kmeans-plus.
When using Track 2 of the ZeroSpeech Challenge's datasets downloaded from https://download.zerospeech.com, the ZeroSpeech toolkit https://github.com/zerospeech/benchmarks can be used for evaluation. When working with LibriSpeech or BuckEye, our evaluation scripts can be used, found in our GitHub repository: https://github.com/s-malan/evaluation.
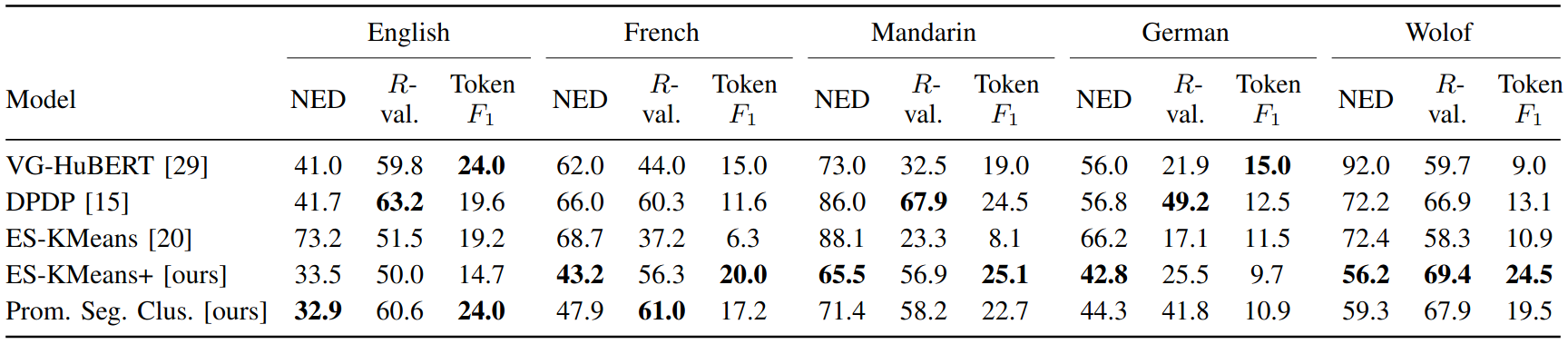
Table I shows the results we get on the five-language ZeroSpeech Challenge. For more results and their discussions please refer to our paper.
Resynthesis is not covered in the paper, but it provides insights into how intelligible the systems are. The basic premise is to recreate target (hold-out) utterances by using the learned lexicon to replace word-like segments in the original utterances with segments out of the same lexicon cluster. This gives an audible representation of how well our systems have "learned" the language. We provide one example with a target utterance and its resynthesized versions.
| Resynthesis Example | ||
|---|---|---|
| Original/Target | Prom. Seg. Clus. | ES-KMeans+ |